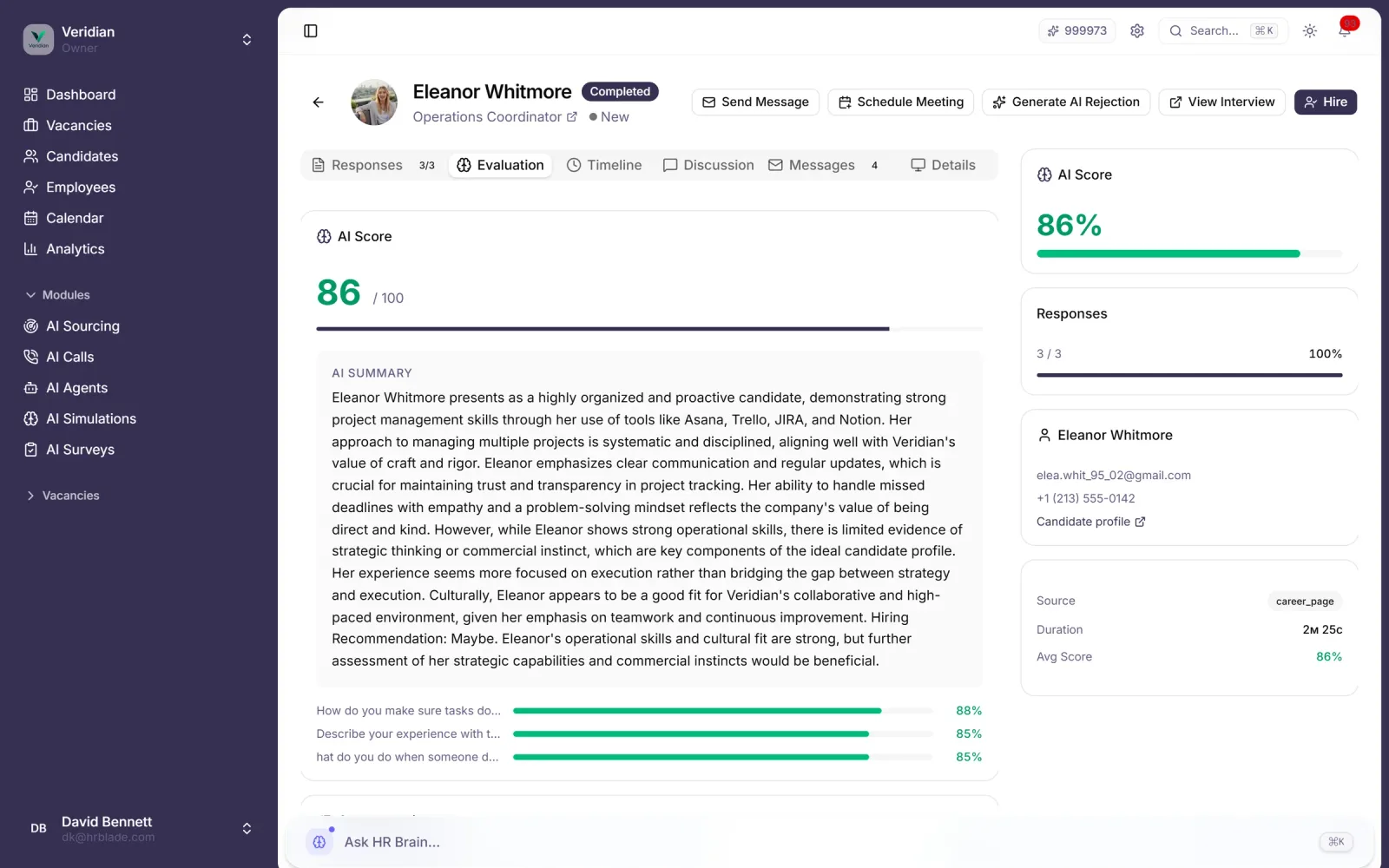
Motor de integridad multicapa que flaggea texto generado por IA, copy-paste de respuestas públicas, comportamiento sospechoso y envíos externalizados — con un 94 % de precisión de detección.
Iniciar prueba gratuita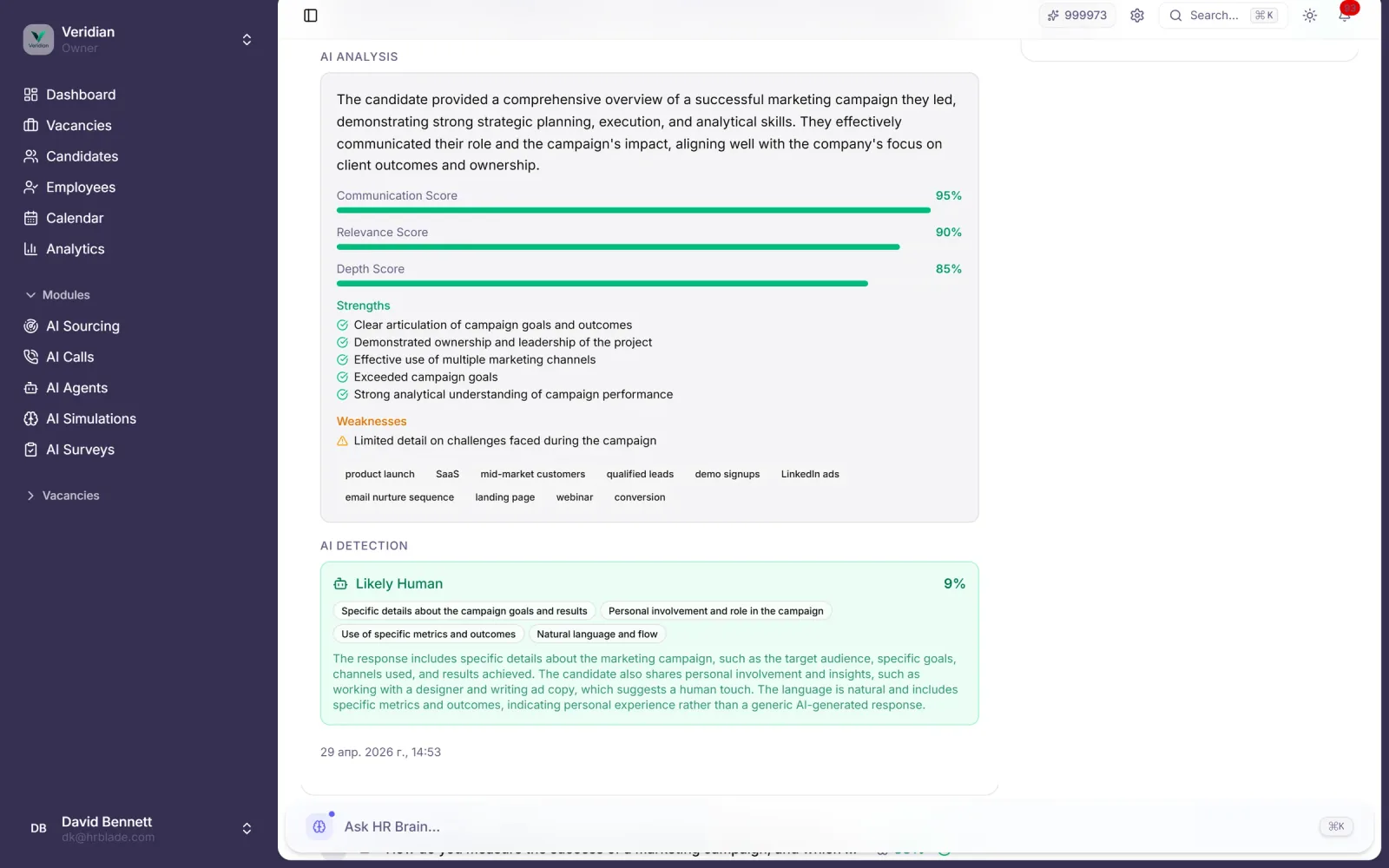
Clasificador anti-LLM que flaggea respuestas escritas por ChatGPT, Claude o Gemini en envíos en inglés, español y alemán.
Detección de cambio de pestaña durante evaluaciones, anomalías de frecuencia de pegado, patrones de tiempo en pregunta, inspección del histórico de edición.
Cada respuesta flaggeada incluye razonamiento, comparación con la fuente y score de confianza para que el reclutador la revise.